Multiple datasources are very common in
report development. We would first join tables from different databases before
performing subsequent computations, such as filtering, grouping and sorting.
With virtual data source or table join, reporting tools like JasperReport and
BIRT can in some degree realize these computations based on joins between
datasources. But they are difficult to master.
esProc, however, can be used to make the
reporting tool’s handling of this situation easier, thanks to its powerful structured data computing, support for heterogeneous
datasources and integration-friendly feature. The following is to illustrate
how to deal with computations based on multiple datasources joins.
MySQL database has a table - sales - holding each day’s orders of
more than one sellers and in which SellerId is the ID numbers of the sellers. emp is an MSSQL table having sellers’
information, in which EId is the ID numbers of the sellers, Name is their names
and Dept is the departments. We want to display data of OrderID, OrderDate,
Amount, Name and Dept in the report with the condition that order dates are
limited to the past N days (say 30 days) or the data should belong to certain
popular departments (like Marketing and Finance).
As orderID, OrderDate and Amount exist in sales while Name and Dept exist in emp, the two tables from different
databases need to be joined first; then conditional filtering will be
performed. Some of the source data are as follows:
Table sales

Table emp

esProc code for doing this:

A1=myDB1.query("select
* from sales")
This line of code retrieves all records
from sales of myDB1, which represents
MySQL database. query function is
used to execute SQL queries and can receive external parameters. A1’s result is
as follows:
A2=myDB2.query("select
* from emp")
This line of code retrieves all records
from emp of myDB2, which represents
MSSQL database.
A3=A1.switch(SellerId,A2:EId)
This line of code switches A1’s SellerId
field to its corresponding records in A2 through the relational field EId. A3’s
result is as follows (data items in blue have members of lower level):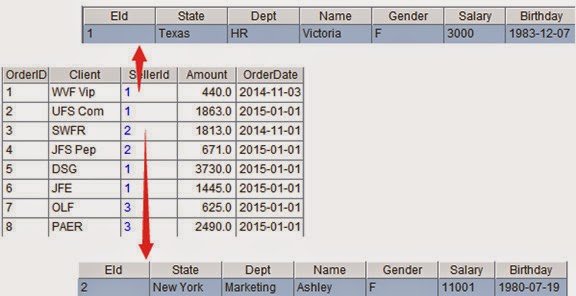
When there is no corresponding record for a
data item in A1’s SellerId, switch
function will by default retain the record this data item resides but display the
record’s SellerId value as null. The effect is similar to the left join. If
inner join is needed, use @i option
in the function, like A1.switch@i(SellerId,A2:EId).
A4=A3.select(OrderDate>=after(date(now()),days*-1)||
depts.array().pos(SellerId.Dept))
This line of code filters the result of
join according to two conditions. The first one, represented by the expression OrderDate>=after(date(now()),days*-1), is to
select orders during the past N days (corresponding parameter is days); the second, represented by
expression depts.array().pos(SellerId.Dept),
is that the orders should belong to certain specified departments
(corresponding parameter is depts). The operator “||” means the logical relationship
“OR”.
now function represents the current time and date function converts it into the date. after function can represent the relative time, after("2015-01-30",-30), for example, means
pushing the current time back by thirty days, i.e. 2015-01-01. With different
options, the function can represent the relative time based on year, quarter,
month and second.
array function converts a string into a set by the delimiter. "Marketing,Finance".array(),
for instance, is equivalent to ["Marketing ","Finance"].
The function’s default separator is the comma, but we can specify other
separators for it. pos function
locates a member in the set, ["Marketing
","Finance"].pos("Finance"), for instance, is
equivalent to 2 – or true logically. If the member doesn’t exist in the set,
then null will be returned - which means false logically.
Note that SellerId.Dept represents the Dept
field of the corresponding record of SellerId field. It can be seen that, after
fields are switched by switch
function, the table relation can be represented through object style access,
which is intuitive and simple, especially when establishing the multi-table and
multilayer relation.
days and depts are parameters
passed from the reporting tool. If they get assigned with 30 and "Marketing,Finance"
respectively, A4’s result will be as follows:
A5=A4.new(OrderID,OrderDate,Amount,SellerId.Name:Name,SellerId.Dept:Dept)
This line of code gets fields the report
needs from A4. SellerId.Name
and SellerId.Dept represent respectively
Name and Dept in emp. The operator “:”
means renaming. A5’s result is as follows:
Now all data are ready for the report.
Finally we just need to return A5’s two-dimensional table to the reporting tool
with result A5. esProc offers the JDBC
interface to be integrated with the reporting tool that will identify it as a
database. See related documents for the integration solution.

Define two parameters – pdays and pdepts – in the report, corresponding to the two parameters in the esProc script. Click Preview to view the report:

The way the reporting tool calls the esProc
script is the same as that it calls the stored procedure. Save this script as afterjoin1.dfx, for instance, and it can
be called by afterJoin1 $P{pdays},$P{pdepts}
in JasperRreport’s SQL designer.
With the
assistance of esProc, the reporting tool can tackle more complicated
computations based on multi-dasource joins. To find out, for example, the top three
days when each seller’s sales amount increases the most rapidly after a certain
date, and to display names, dates of the three days, amount and growth rate.
esProc script:
A1=myDB1.query("select
* from sales where OrderDate>=?",beginDate)
This line of code retrieves orders after a
certain date from sales, in which beginDate is the parameter passed from the
reporting tool, whose value let’s assume to be “2015-01-01”. Then A1’s result
is as follows:
A2=myDB2.query("select
* from emp")
This line of code retrieves all records
from emp as follows:
A3=A1.switch(SellerId,A2:EId)
This
line of code switches A1’s SellerId field to its corresponding records in A2.
Result is as follows:
A4=A3.group(SellerId)
This line of code groups orders by
SellerId. In the following figure, the left part is A4’s result and the right
part shows two orders in detail.
A5=A4.(~.groups(OrderDate,SellerId;sum(Amount):subtotal))
This line of code groups each SellerId’s
orders by OrderDate and SellerId and summarizes the amount of each group. That
is, it computes the sales amount of per seller per day. The result is as
follows:
In this line of code, “A4.()” means
computing A4’s members by loop. “~” in the parentheses represents a variable of
members, i.e. the record of order corresponding to a certain SellerId. “~.groups()”
means applying groups function to
each member. groups function groups
data and summarizes them simply, while group
function only groups data.
A6=A5.(~.derive((subtotal-subtotal[-1])/subtotal[-1]:rate))
This line of code computes daily growth
rate of the sales amount of each seller. The result is as follows:
In this line of code, derive function is used to append a new field – rate – to each group. The arithmetic is “(sales
amount of the current day – sales amount of the previous day)/ sales amount of
the previous day”. We can see that subtotal[-1] is
used in esProc to represent the sales amount of the previous day. This makes
the computing of relative position easier.
Note that, since there is not the “sales
amount of the previous day” for the first record, its growth rate is Null.
A7=A6.(~.select(#!=1))
This line of code removes the first record
of each group in A6 (because its growth rate is a meaningless Null).
select function queries records we want. “#” is the loop number and thus “#!=1”
means the number is not equivalent to 1. The same effect can be achieved by delete function too, but with lower
performance. That’s because the former returns only the references while the latter
needs to modify the real data.
A8=A7.(~.top(-rate;3))
This line of code gets records of the top
three days when the growth rate of each seller’s sales amount is the biggest. top function gets the top N records
according to a certain field (or the expression of certain fields). A8’s result
is as follows:
A9=A8.union()
This line of code unions every group of
data in A8 together to create a new two-dimensional table, as shown below:
A10=A9.new(SellerId.Name:Name,OrderDate,subtotal,rate)
This line of code gets fields as required.
Then the final result is as follows:
result A10
This line of code returns A10’s
two-dimensional table to the reporting tool. See the first example for the
report design, which will be omitted here.
No comments:
Post a Comment