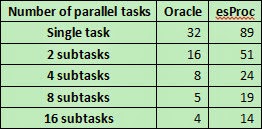
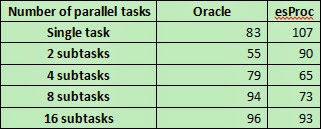
In this article, we’ll test the performance
of esProc in handling in-memory small data computing, and compare with that of Oracle
when performing the same computation.
The test involves two cases: normal simple
computing and complicated related computing:
The test data used in normal computing is
order information, as shown below:
ORDERID CLIENT SELLERID AMOUNT ORDERDATE
1 287 47 5825 2013-05-31
2 89 22 8681 2013-05-04
3 47 67 7702 2009-11-22
4 76 85 8717 2011-12-13
5 307 81 8003 2008-06-01
6 366 39 6948 2009-09-25
7 295 8 1419 2013-11-11
8 496 35 6018 2011-02-18
9 273 37 9255 2011-05-04
10 212 0 2155 2009-03-22
esProc script for normal computing:
A
|
B
|
|
1
|
=date("2013-09-01")
|
=date("2013-11-01")
|
2
|
=file("/ssd/data/orders.b").import@b()
|
|
3
|
=A2.select(ORDERDATE>A1 &&
ORDERDATE<B1)
|
|
4
|
=A3.groups@u(CLIENT,SELLERID;sum(AMOUNT):S,count(ORDERID):C)
|
|
5
|
=A4.select(C==13)
|
|
6
|
result A5
|
|
Note about the esProc script: A2 imports
data in one go and its result can be used repeatedly. So it will not be counted
in the execution time of in-memory computing, which only includes the time spent
in executing steps from A3 to A6.
SQL script that Oracle uses:
select
client,sellerid,sum(amount) s,count(orderid) c
from orders
where
orderdate>to_date('2013-09-01','yyyy-MM-dd')
and orderdate<to_date('2013-11-01','yyyy-MM-dd')
group by
client,sellerid
having
count(orderid)=13
There are 8 million rows of data in orders.
Test result:
esProc
|
Oracle
|
|
Execution
time
|
0.570
seconds
|
0.623
seconds
|
Note: Execute Oracle’s SQL script four
times and get the average of the last three times. In this way Oracle can make
full use of its in-memory cached data. As for esProc script, we’ll execute it
three times and get the average time.
During related computing testing, esProc
imports the following files - orders.b,
orders_detail.b, employee.b, department.b
and performance.b. The relationships
among them are as follows:
esProc script for data importing:
A
|
B
|
|
1
|
="/ssd/data/"
|
|
2
|
=file(A1+"orders_detail.b").import@b()
|
|
3
|
=file(A1+"orders.b").import@b().primary(ORDERID).index()
|
|
4
|
=file(A1+"employee.b").import@b().primary(EID).index()
|
|
5
|
=file(A1+"department.b").import@b().primary(DEPT).index()
|
|
6
|
=file(A1+"performance.b").import@b().primary(EID).index()
|
|
7
|
=A2.switch(ORDERID,A3:ORDERID)
|
=A3.switch(SELLERID,A4:EID)
|
8
|
=A4.switch(DEPT,A5:DEPT)
|
=A5.switch(MANAGER,A4:EID)
|
9
|
=A4.switch(EID,A6:EID)
|
=A2.select(ORDERID.SELLERID.DEPT.MANAGER.EID.BONUS>6000)
|
10
|
=B9.groups@u(ORDERID.CLIENT:CLIENT,ORDERID.SELLERID.EID.EID:EID,PRODUCT;sum(PRICE*QUANTITY):S,count(ORDERID):C)
|
|
11
|
=A10.select(S>24500 && S<25000)
|
result A11
|
Note about esProc script: The code from A1
to A9 imports files and establishes the relationships (import and switch). This
is done at one time and the result can be used repeatedly. This part of
execution will not be included in the execution time of in-memory computing.
The execution time is the time spent in executing steps from B9 to B11.
Oracle’s SQL:
select
o.client,o.sellerid,od.product,sum(od.price*od.quantity) s,count(o.orderid) c
from
orders_detail od left join orders o on o.orderid=od.orderid
left join
employee e on o.sellerid=e.eid
left join
department d on d.dept=e.dept
left join
employee e1 on d.manager=e1.eid
left join
performance p on p.employeeid=e1.eid
where
p.bonus>=6000
group by
o.client,o.sellerid,od.product
having
sum(od.price*od.quantity) between 24500 and 25000
Test one: Both the orders table and the orders_detail
table have 8 million rows. There are less than 1,000 rows in other tables.
Test result:
esProc
|
Oracle
|
|
Execution
time
|
4.9
seconds
|
9.7
seconds
|
Test two: Both the orders table and the orders_detail
table have 4 million rows. There are less than 1,000 rows in other tables.
Test result:
esProc
|
Oracle
|
|
Execution
time
|
2.3
seconds
|
5.1
seconds
|
Similarly, we execute Oracle’s SQL script
four times and get the average of the last three times, in order to let Oracle
make full use of its in-memory cached data. We execute esProc script three
times and get the average.
Conclusion:
For small data in-memory computing, when
the computation is simple without file relating, esProc is a little faster than
Oracle. This is probably because, though Oracle can cache data, it still needs
to convert the cached data (without using the physical disk) before processing
it. When handling the complicated related computing, esProc works much faster
than Oracle. The reason is that Oracle uses the hash algorithm to join two
tables, while esProc uses a pointer to reference foreign key values, and thus
does not need to compute hash values and query matching values.
Therefore, when there is enough available
memory capacity, esProc can achieve much higher performance than conventional relational
database if we import data into memory and arrange it beforehand. esProc is great
in achieving high performance for in-memory computing.
Test environment:
CPU: Core(TM) i5-3450 four cores, four threads
Memory capacity: 16GB
OS:CENT OS
Oracle11g:Maximum memory
capacity is 14G
esProc 3.1 version: Maximum memory capacity
is 14G