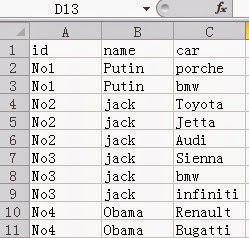
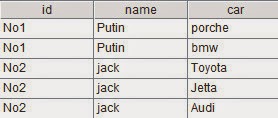
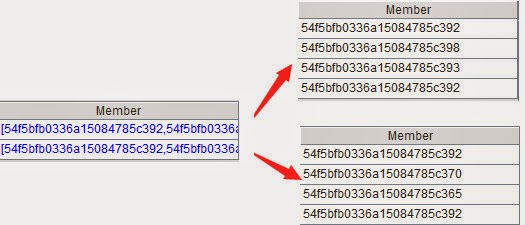
Problem source: http://bbs.csdn.net/topics/390611005
Below is JSON data (s.json) the system
acquires:
|
{
"SUCCESS": [
{
"MESSAGE": "IMEI
Service List",
"LIST": {
"MOVISTAR SPAIN": {
"GROUPNAME":
"MOVISTAR SPAIN",
"SERVICES": {
"3": {
"SERVICEID": 32,
"SERVICENAME": "MOVISTAR NOKIA INSTANTE",
"CREDIT": 4,
"TIME": "1-30
Minutes",
"INFO":
"<p style=\"text-align: center;\">…… </p>",
"Requires.Network": "None",
"Requires.Mobile": "None",
"Requires.Provider":
"None",
"Requires.PIN": "None",
"Requires.KBH": "None",
"Requires.MEP": "None",
"Requires.PRD": "None",
"Requires.Type":
"None",
"Requires.Locks": "None",
"Requires.Reference": "None"
},
"8": {
"SERVICEID": 77,
"SERVICENAME":
"MOVISTAR NOKIA 20 NCK",
"CREDIT": 12,
"TIME":
"1-30 Minutes",
"INFO":
"<p style=\"text-align: center;\">……</p>",
"Requires.Network":
"None",
"Requires.Mobile": "None",
"Requires.Provider": "None",
"Requires.PIN": "None",
"Requires.KBH": "None",
"Requires.MEP":
"None",
"Requires.PRD": "None",
"Requires.Type": "None",
"Requires.Locks": "None",
"Requires.Reference": "None"
}
}
},
"VODAFONE SPAIN": {
"GROUPNAME":
"VODAFONE SPAIN",
"SERVICES": {
"5": {
"SERVICEID": 50,
"SERVICENAME": "VODAFONE NOKIA BB5 SL3",
"CREDIT": 5,
"TIME":
"1-60 Minutes",
"INFO":
"<p style=\"text-align: center;\">……</p>",
"Requires.Network": "None",
"Requires.Mobile": "None",
"Requires.Provider": "None",
"Requires.PIN": "None",
"Requires.KBH":
"None",
"Requires.MEP": "None",
"Requires.PRD": "None",
"Requires.Type": "None",
"Requires.Locks": "None",
"Requires.Reference": "None"
},
"10": {
"SERVICEID": 95,
"SERVICENAME":
"VODAFONE SONY&;SONY ERIC(RAPIDO)",
"CREDIT": 16,
"TIME":
"1-24 Hours",
"INFO":
"<p style=\"text-align: center;\">……</p>",
"Requires.Network": "None",
"Requires.Mobile": "None",
"Requires.Provider": "None",
"Requires.PIN": "None",
"Requires.KBH": "None",
"Requires.MEP": "None",
"Requires.PRD":
"None",
"Requires.Type": "None",
"Requires.Locks": "None",
"Requires.Reference": "None"
}
}
}
}
}
],
"apiversion": "2.0.0"
}
|
Based on above JSON data, you need to
update database tables with property values of corresponding section. Below is
the two tables need updating:
Create table [dbo].[Groups]
(
[ID] [int] IDENTITY(1,1) NOT NULL, --id
[Groupname] [nvarchar] (50) not null default(''), --name
[groupid] [int] not null default(0),
CONSTRAINT [PK_Groups_id] PRIMARY KEY
CLUSTERED
(
[id] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
CREATE TABLE [dbo].[Services](
[id] [int] IDENTITY(1,1) NOT
NULL, --id
[Serviceid] [int] not null default(0),
[Servicename] [nvarchar] (50) not null default(''),
[groupid] [int] not null default(0),
[Credit] [decimal] not null default(0.00),
[Time] [nvarchar] (50) not null default(''),
[INFO] [nvarchar] (3000) not null default(''),
[Network] [nvarchar] (100) not null default('none'),
[Mobile] [nvarchar] (100) not null default('none'),
[Provider] [nvarchar] (100) not null default('none'),
[PIN] [nvarchar] (100) not null default('none'),
[KBH] [nvarchar] (100) not null default('none'),
[MEP] [nvarchar] (100) not null default('none'),
[PRD] [nvarchar] (100) not null default('none'),
[Type] [nvarchar] (100) not null default('none'),
[Locks] [nvarchar] (100) not null default('none'),
[Reference] [nvarchar] (100) not null default('none'),
[isstatus] [nvarchar] (1) not null default('0'),
[remark] [nvarchar] (255) not null default(''),
[Pricingid] [int] not null default(0),
CONSTRAINT [PK_Services_id] PRIMARY KEY
CLUSTERED
(
[id] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
The property for SERVICES is groupid, such
as 3, 5, 8, 10. The rest of the fields correspond to other properties
respectively. That the property names under LIST and SERVICES are not fixed
makes the data parsing difficult. Compared with common high-level languages,
esProc supports dynamic data structure and set operations and thus can provide
easy solution. esProc script is as follows:

A1: Read JSON file into strings and convert them into a cascaded table sequence with rows and columns using import@j().

A2-A3: Create empty table sequences based
on the two target tables, in order to store parsing results that will be
updated into the database in one go.
A4-B4: Run a loop in A4 and calculate the
number of sections under LIST in B4.
B5-C6: Get the content of each section of LIST by loop and calculate the number of sections under SERVICES in C6.

C7-D8: Get property names and values from each SERVICES’s section by loop.

D9-D10: Write parsing results respectively back into the empty table sequences in A2 and A3.

A11: Update A2’s data into groups table through the primary key groupid.

A12: Update A3’s data into services table through the primary key
Serviceid.