If k (a single field or a
combination of fields) is table M’s primary key, and k, at the
same time, exists in table B, then k is regarded as B’s foreign
key. The foreign key defines a relationship between two tables and is one of
the most important concepts for structured data computing. Through object
references, esProc makes foreign key easy to function. The following examples
aim to illustrate the how foreign key is used in esProc.
Example 1 Associate a referenced table and a
referencing table
Order (containing orders information) is the referencing table, emp(containing employee information) is the referenced table. It is
required to connect emp with order and display emp’s Name field, Gender field and Salary
field and order’s OrderID field and Amount field in the result table.
Note: Besides emp table and order
table used here, dep table (containing departments information) is to be
used in subsequent examples. The relationship between emp and order/dep through the foreign key is shown as
follows:

Data may
originate from databases or text files. For example:
order=esProc.query("select
OrderID,SellerId,Amount,OrderDate from sales")
emp=esProc.query("select
EId,Name,Gender,Birthday,Dept,Salary from emp")
dep=esProc.query("select
* from department")
esProc
code for doing this:
A3=order.switch(SellerId, emp:EId)
A4=order.new(OrderID,Amount,SellerId.Name,SellerId.Gender,SellerId.Salary)
Computed result:

Code explanation:
A3: Replace records of order’s SellerID with their corresponding
ones in emp to create a foreign key relationship between the two
tables.
A4: Get OrderID field and Amount field from
order, and get Name, Gender and Salary field from emp through foreign
key references. We can see that, with object references, fields in emp
can be accessed directly from order, thus saving us the trouble of
writing complex and difficult join statements.
Example 2: Query referencing table according to
condition existing in referenced table
Find orders
signed by female sellers whose salary is greater than 10,000.
esProc
code for doing this:
A3=order.switch(SellerId, emp:EId) / the same as above example
A5=order.select(SellerId.Salary>10000
&& SellerId.Gender=="F")
Computed results:

Click the above hyperlinks in blue and corresponding employee information will be shown:

Example 3: Group data
according to referenced table
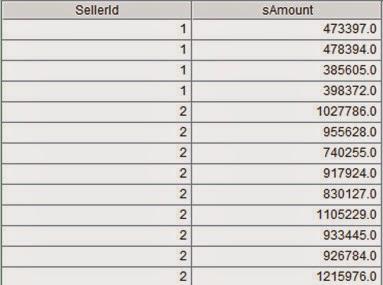
Compute sales amount of each department.
esProc
code for doing this:
A3=order.switch(SellerId, emp:EId) / the same as above
example
A5=order.groups(SellerId.Dept;sum(Amount))
Computed results:

You can rename fields, like order.groups(SellerId.Dept:dt;sum(Amount):amt). The effect of name changing is shown below:

Example 4: Complex
association between multiple tables
Find
managers of departments whose sales amount is greater than 50,000.
esProc code for doing this:
A3=order.switch(SellerId,
emp:EId)
A4=dep.switch(Manager,emp:EId)
A5=emp.switch(Dept,dep:DeptNo)
A6=order.groups(SellerId.Dept:dt;sum(Amount):amt)
A7=A6.select(amt<=50000).(dt).(Manager).(Name)
Computed results:

Code explanation:
A3, A4,
A5:Create complete foreign key relationships.
A6: Compute sales amount of each department (See above example). The result is:

A7:Use object references to solve the problem intuitionally.
Expression A6.select(amt<=50000).(dt).(Manager).(Name) can
be divided into four steps according to full stops. They are:
1. Find records whose sales amount
is greater than 50,000 from A6.
2. Get records corresponding to those
in dt field (from dep table)
3.
Get records corresponding to those
in Manager field (from emp table)
4. Get Name field.
Details are as follows:
A6.select(amt<=50000)
.(dt)
.(Manager)
.(Name)