In an esProc table sequence, a single or multiple fields can be used
as a primary key. We can make query based on the primary key using some special
functions, which can both simplify the code and increase computational
performance effectively.
1.find and pfind
Primary keys are common used in database tables. The value of a primary key
field is used to uniquely identify a record, so primary keys must not contain
identical values, which is a mandatory rule in many databases.
In esProc, it is assumed that
the primary key has unique value
among the records. But no mandatory check will be executed and there won't be an error reporting even if
there are identical primary key values. Both T.find(v) function and T.find(v) function can be used to query records in table
sequence T according to v, the primary key value. find returns the first record found and pfind returns the sequence number of this
record.
It is not a must to define a primary key. When no primary key is defined
in esProc, the first field will be used as the primary key. If specified fields
are needed to be defined as the primary key, T.primary(Fi,…) function, which means defining Fi,… as the primary key of
table sequence T, will be used.
Usually, conventional position functions T.select() and T.pselect()
are used to query records in a table
sequence. Now we’ll compare usages of this pair of functions with pfind and find.
Here table EMPLOYEE in demo database is the table sequence on
which query will be executed. Add FullName
field to it so that the employees’ full names can be used to make query:

In order to show the performance advantages of using the primary key to query data, 10,000 full names will be generated randomly and pselect and pfind will be used respectively to make query according to these full names. Compute the time these two methods will take:

Based on the same data, A5 and A9 use pselect and pfind respectively to query positions of the records in the table sequence. In A9, primary function is used to set the primary key for the table sequence before pfind starts to work. A6 and A10 compute respectively the milliseconds the queries will take:

But the query results in A5 and A9 are same:

Using similar method, we can compare select function and find
function. To keep in line with find
function, @1 option is used in select function to get the first result
and return it:

A6 and A10 compute respectively the milliseconds the queries will take:

Still, the query results in A5 and A9 are same:

It can be seen easily from the comparison that the query functions
based on the primary key are much more efficient than conventional position
functions.
2.Primary key and the index table
Why, in esProc, will the efficiency increase significantly when the primary
key is used to make query? The reason is that the index table of the primary
key has been used for computing.
During calling a primary
function, or making query based on the primary key in a table sequence without
an index table for the first time, an index table will be generated according
to the primary key. While the index table is being generated, a hash table will
be created according to all values of the primary key, which will divide
primary key values into many groups by their hash values. These hash values are
the corresponding group numbers.
Normally, when we query a certain record in a table sequence
according to the field value, we need to examine the records one by one until
the target is found. For a table sequence containing n records, an average of n/2 examinations
are needed.
Thanks to the index table, it would be different to query a certain
record in a table sequence according to the value of the primary key field. The
hash values will be computed first according to the primary key values, which
enable us to find out directly the corresponding groups in the index table.
Then we just need to examine records of the same group. In the same way, for a
table sequence containing n records,
if its primary key values are distributed in k groups according to hash values, only an average of n/2k comparisons are needed. Using this
method, despite hash values must be computed before an index table is generated
and the query is executed, the number of comparisons is reduced significantly,
and in particular, the index table needs to be generated only once. Therefore,
the more the data in a table sequence and the times needed for a query, the
higher the efficiency.
During computing, T.index(n)function can be used to create an index table for T’s primary key in advance. n represents the length of the index
table. Default value will be used if there is not a defined length.
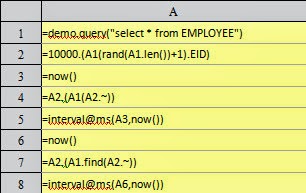
This time 10,000 sequence numbers of employees are generated randomly. A4 finds the corresponding records directly according to these sequence numbers; A7 still uses find function to find records. A5 and A8 compute respectively the time the two methods will take:

We can see that it is much faster to locate records using sequence numbers directly. Because this method doesn’t compare field values, nor does it compute the hash values and create an index table. The query results in A4 and A7 are same:

Thus it can be seen that suitability should be taken into
consideration if the index function of the primary key in a table sequence is
to be used to increase efficiency in esProc.
3.switch function
Besides find function and pfind function, switch function query records according to the primary values too. It will also use the index table of the primary key automatically in dealing with the operation. For example:
Both A2 and A3 contain personnel information imported from binary text file PersonnelInfo, as shown below:

A4 contains states information:

In both A6 and A9, State field of PersonnelInfo is switched into corresponding states information. Their difference is that A6 uses select@1 function while A9 uses switch function. A7 and A9 compute respectively the time the two methods will take:

After the code in the cellset is executed, values of A2 and A3 are same, as shown below:

State field has been switched into corresponding records in states
information table.
Before switch is executed, an index table will also be created for corresponding
fields in the table sequence. In this example, an index table is created for ABBR field of states information table
in A4 to increase the matching efficiency. So switch function should be properly used when foreign key fields for
referencing are to be generated.
No comments:
Post a Comment