MongoDB allows storing unstructured data in
it. But it is somewhat difficult to export the data as standard structured
data. esProc, however, makes it an easy job, with MongoDB’s cooperation. Let’s
look at the steps for doing this.
Below is some data from Collection test:
/* 0 */
{
"_id" :
ObjectId("5518f6f8a82a704fe4216a43"),
"id" : "No1",
"cars" : {
"name" : "Putin",
"car" : ["porche",
"bmw"]
}
}
/* 1 */
{
"_id" : ObjectId("5518f745a82a704fe4216a44"),
"id" : "No2",
"cars" : {
"name" : "jack",
"car" : ["Toyota",
"Jetta", "Audi"]
}
}
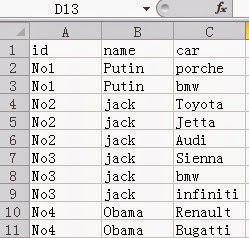
You need to export it as a CSV file with
the following layout:
esProc code:

A1: Connect to MongoDB. Connection string
format is mongo://ip:port/db?arg=value&…
A2: Retrieve data from MongoDB using find function and generate a cursor with
the retrieved data. The collection name is test.
There are no filtering criteria and all fields except _id are desired. find functions in esProc and MongoDB are
alike. The esProc version follows MongoDB for syntax of filtering criteria.
A3: Retrieve desired fields to create a structured
two-dimensional table, which is in the form of cursor. In the code, ~
represents every document in A2; conj
function concatenates data together.
A4: Export data from A3 as a comma separated
text file. @t means exporting with column names. esProc engine manages buffers
automatically, fetching a batch of data each time from the cursor into the
memory for computation.
A4: Close MongoDB connection.

A3: Run a loop to fetch data from the cursor into memory, 1,000 rows each time. A3’s working range is the indented B3 and B4, in which A3 is used to reference the loop variable. A3’s data is as follows:

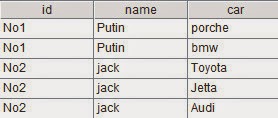
B3:Convert the current batch of data to structured two-dimensional table, as shown below:
B4:Append the result of
processing the current batch to the file. @a means data appending.
No comments:
Post a Comment