The MERGE statement provided by databases
like MSSQL and ORACLE is very convenient for updating tables. But it is not as
convenient as it is expected to be when the source table and target table exist
in different databases. In this case esProc is able to rise to the occasion and
assists the operation.
source and target are parameters
representing two tables of the same structure but of different data in two
databases. The source table will be used to update the target table based on
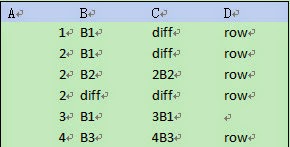
their primary keys. For example, both Table
1 and Table 2 (as shown below)
have a primary key consisting of column A and column B:

After Table 1 is updated by Table 2, it will be as follows:
esProc code:

A1,A2:Get the source table’s
primary key from the system tables and store it in variable pks; the result is “A,B”. Databases vary
in how to get the primary key. Here MSSQL will be used as an example.
myDB2/myDB1 represents the database where source/target resides.
A3,A4:Retrieve data from source and target as cursors; sort data according to the merging field (the
primary key) for the subsequent MERGE operation.
A5:Perform a left-join
with target and source. @x represents cursor-handling and @1 represents the
left-join. The macro ${columns} is used to
convert a string to an expression.
A6:Fetch data from A5’s cursor by loop, 1,000 rows each time. A6 is used in the loop body B6-B9 to reference the loop variable. Below is the structure of the operation performed in A6:

B6,B7:Select rows
need to be inserted and modify the target.
@i option means performing only the INSERT, without scanning the whole table.
B8,B9:Select rows for
updating the table and modify the target.
@u means performing only the UPDATE. array
function gets a list of the field names.

The
above approach also applies to databases that don’t support the MERGE
statement, like MySQL.
No comments:
Post a Comment