1.Testing purposes
Testing esProc and Oracle on the same hardware for single machine performance, to compare the two for performance difference either in large data volume single task computation or small volume multiple tasks concurrent computation use cases. 2.Testing contents and methods
Data volume:Small data volume: single fact table around 10G. To avoid the testing results being affected by operating system cache, multiple concurrent request will be accessing different fact tables.
Large data volume: single data table is about 100G.
Algorithm category: Testing the performance of several typical SQL algorithms, including data scan, grouping, join and large grouping, etc.. Note that the use of these simple algorithms is for better understanding and direct comparison of the performance, not because esProc and SQL are identical to each other. In fact, the two of them focus on different things. esProc is good at procedure computation with more complicated business logic, while SQL is for computation of average complexity. Complicated algorithm can be realized with different SQL execution plan, which is out of manual control, and thus not good for comparison. We'll not do such test.
Category of Use Cases:Each algorithm are tested with multiple use cases according to the width of the table, data types, etc..
Among them, the purpose for large grouping use cases is to test the scenario when the resulting data sets of the grouping is too large to be fit in the memory. So this report will only test the situation of parallel computing with 100G large data volume, rather than concurrent computing with small data volume.
Note: the article esProc Oracle Single Machine Performance Comparison Process is an
appendix of this report. Please refer to it for details such as data
structures, test code, test reproduction, etc..
3.Testing Environment
Testing
Machine:Dell Power Edge T610
CPU:Intel Xeon E5620*2
RAM:20G
HDD:Raid5 1T
Operating System:CentOS 6.4
JDK:1.6
Oracle Version:11g
esProc Version:3.1
4.Data Description
The
volume of the data is decided by the amount allowed by exported text file.
During the single machine test, esProc uses proprietary file format.
As the purpose is mainly to test big data computation and whole table scan performance, no primary key or index is build for any table in the database. For purpose of big data computation test, the primary key field described in data structure simply means that this field is the logic primary key. No data repetition is allowed. Primary key is not physically built.
4.1 Data tables and the associated tables
Facts TableT1, T11, T12, T13
Wide table T1, T11, T12, T13, is to simulate the fact table with large numbers of data fields. Total number of designed fields is 100. The four tables have identical structures. T11, T12, T13 are used for small data volume multi-task concurrent access to different tables to avoid system cache.
Fact Table T2, T21, T22, T23
Narrow tables T2, T21, T22, T23 are used to simulate fact tables with less fields. Total number of designed fields is 11. The four tables have identical structures. T21, T22, T23 are used for small data volume multi-task concurrent access to different tables to avoid system cache.
Fact tables are the main data source for this test, and are used in scan, group, join computation. Tests are done for both large and small data volumes, with are controlled by inserting different rows of records.
Dimensional table DL2, DL6, DD2, DD6, DC2, DC6
Dimension table is only used to test the join (and multiple joins) use cases. These dimension tables and fact tables will be joined, so will the dimension tables. These tables have fixed data volume.
4.2 Data volume
Numbers in the table stands is the number of record rows, not the number of occupied spaces in bytes.
Note:
the goal for large data volume single machine test is to test the performance
when the memory used by the data is well above physical memory. Our test
standard is the size of a single fact table to be approximately 5 times the
size of physical memory. The memory used by dimension table is far below the
physical memory. Actual number of record rows used could be adjusted according
to the configuration of the machine.
The
goal for small task concurrent single machine test is to show the performance
when memory occupied by the data is less than the physical memory, and the
computation could be done completely in the memory. Our test standard is to use
a single fact table of 50% the size of the physical memory. Memory used by
dimension table is far less than the physical memory. Actual number of record rows
used could be adjusted according to the configuration of the machine.
T11/T12/T13 and T21/T22/T23 are only used for small data volume multi-task
concurrent test.
To make sure that esProc and Oracle is computing against exactly the same data, we will export the data generated in Oracle to a binary file format defined by esProc, as the data source for esProc during the test.
5.Use Case Description
For
better understanding, all test logic will be described in SQL.
During
the test Oracle will execute the SQL statement directly, whereas esProc will be
running the equivalent code we write to complete the same computation.
5.1 Use Case For Large Data Volumn Scan
This
use case is large task single machine test. It’s designed to test the
computation performance for whole table scan with large data volume.
Performance for whole table counting, integer sum, float sum, value sum,
integer filter, number filter, character filter, date filter are considered
respectively.

5.2 Use Case For Large Data Volumn Grouping
This use case is large task single machine test. It’s designed to test the grouping computation performance with large data volume, where grouping result record number is small, smaller than the physical memory. Performance for integer grouping, number grouping, character grouping and date grouping are considered respectively.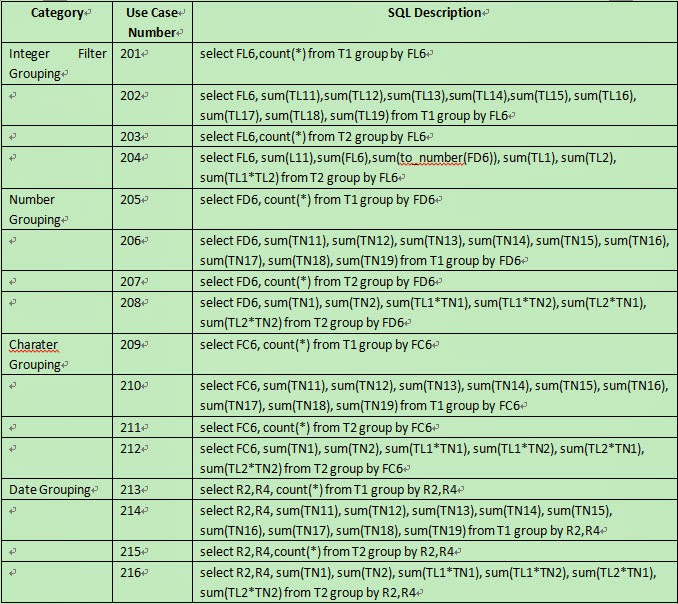
5.3 Use Case For Large Data Volumn Large Grouping
This use case is large task single machine test. It’s designed to test the grouping computation performance with large data volume, where grouping result record number is large, larger than the size of the physical memory, and thus the computation cannot be completed within the memory.
5.4 Use Case For Large Data Volumn Join
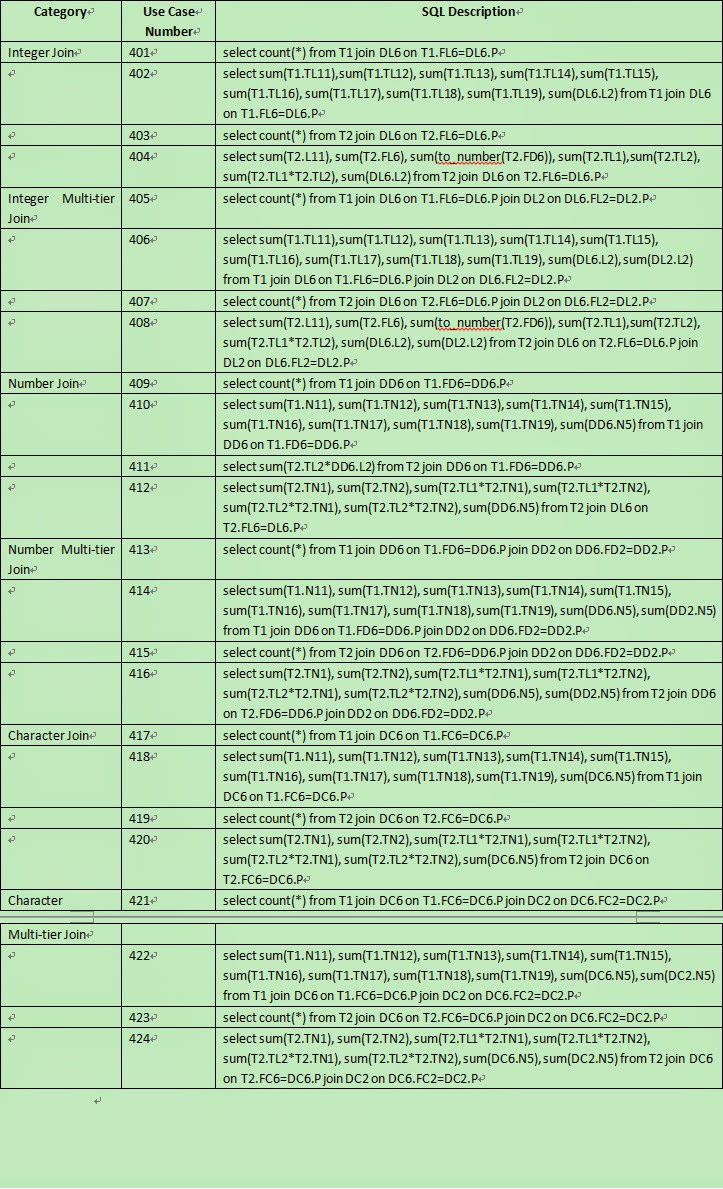
5.5 Use Case For Small Data Volumn Concurrent Test
This use case is to test the multi-task
concurrent computation performance with small data volume. Each task of the
concurrent process is accessing different physical tables/files to avoid OS
cache. Tests were done for scanning, grouping and joining, with the same use
cases as 5.1, 5.2, 5.4 above. However the data volume is small (See data volume
part).
6. Test Use Case
6.1 Small Data Volumn Concurrent Scan
This use case tests Oracle and esProc for
scanning performance against small data volume tables (files). It's done with a
multi-task concurrent access mode. Each task is accessing different table
(file). Among them, Oracle is running 16 parallel processes, while esProcis
running 4 in parallel. Tests proved that this is
the parallel level for highest performance.
Data
Record:

Data
characteristics:
1.Data with blue background is
the peak performance value for this use case. We can see that both Oracle and
esPro is running at peak performance with 1concurrency. Meanwhile in such situation,
Oracle's performance is several times higher than esProc.
2.Performance degrades
significantly both for Oracle and esProc when concurrency number changes from 1
to 2. Oracle still has advantage but the
difference with esProc is not too much.
3.esProc handles each task with
equal performance, while Oracle is extremely unstable.
6.2 Large Data Volumn Scan
This
use case tests Oracle and esProc for their performance during large data volume
tables (files) scanning. Test is done in a single task, none concurrent way. 3
Parallel levels are tested, which are 1, 2 and 4 parallel tasks respectively.

Data
Property:
1.Oracle is at peak performance
with 1 parallel process, and performance starts to degrade with 2. However,
esProc's 4 parallel computation performance is normally higher than 1,
sometimes even several times higher, excepting for a few occurance.
2.esProc demonstrates obvious
advantage over Oracle in this use case test. This could be better observed with
narrow tables and more computation requirements, such as 106, 110 and 114. Use
case 129 and 119 are exceptions where Oracle performs slightly better than
esProc.
3.esProc is observed to be
capable of increasing the computation performance several times with the rise
of parallel numer, such as in the case of use case 106, 110, 114, 118, 122, 126
and 130. These are all for narrow table access, and with more computations.
4.In some cases esProc's
performance could also degrade, for example with use case 103, 107, 111, 115,
119, 119, 123 and 127. These are all for wide table access with less
computation.
6.3 Small Data Volumn Concurrent Grouping
This
use case tests Oracle and esProc for grouping computation performance against
small data volume tables (files). It's done with multi-task concurrent access
mode. Each task is accessing different tables/files.
Data
Record:
Note:
according to the data volume, esProc can choose to do pure in-memory
computation or mix-mode-in-memory-and-out-memory computation. This use case
leverages in-memory computation, while the large data volume grouping use case
in later part of this report is done with mix-mode-in-memory-and-out-memory
computation. Pure in-memory computation has the risk of memory overflow. In
this case we use the parallel level of 1, 2 and 4 to avoid memory overflow. Green character reflects parallel 1, red character is for parallel 2, and black for parallel
4. Oracle forces a mixed mode computation, which avoids memory overflow. Each
task is done with a fixed number of parallel 16 to achieve best performance.

Data
Characteristics:
1.Oracle performs better than
esPro in general, especially with concurrency 1. With this configuration the
performance of Oracle can be several times better.
2.In concurrent task of Oracle is
extremely unstable. Performance varies from task to task, usually with several
times difference. esProc's performance is stable.
3.Date grouping are all done with two-tier grouping, which, as we could see, Oracle performs better.
6.4 Large Data Volumn Grouping
This
use case tests Oracle and esProc for grouping computation performance against
large data volume tables (files). It's done with none concurrent single task
mode for parallel level of 1, 2 and 4.
Data Record:

Data
Characteristics:
1.Oracle is at peak performance
with 1 parallel process, and performance starts to degrade with 2. However,
esProc's 4 parallel computation performance is normally higher than 1,
sometimes even several times higher.
2. esProc's performance is several times higher than Oracle in this use case test.
6.5 Small Data Volumn Concurrent Joining
This use case tests Oracle and esProc for
joining performance against small data volume tables (files). It's done with
multi-task concurrent access mode. Each task is accessing different tables/files.
Oracle has no performance improvement with parallel computation, and thus no
such configuration is used for it. esProc has no performance improvement when
running with more than 4 tasks in parallel. Tests are done for 4 parallel
tasks.
Data
Record:

Data
Characteristics:
1.esProc demonstrates a
performance advantages of 1 or more times over Oracle.
2.esProc's performance variation
among each concurrent task is very small, as compared with Oracle. Oracle's
performance variation remains, but is less than in other use case.
3.Parallel mode yields no performance gain for Oracle, while esProc reaches peak performance with 4 parallel tasks.
6.6 Large Data Volumn Joining
This
use case tests Oracle and esProc for their performance during large data volume
tables (files) join. Test is done in a single task, none concurrent way. Among
them, Oracle reaches peak performance with 1 parallel task, while esProc is
with 4.
Data
Record:

Data
Characteristics:
1. esProc performs better than
Oracle.
2. With multi-tier join, performance degradation for both of them are little.
6.7 Large Data Volumn Large Grouping
This
use case tests Oracle and esProc for grouping computation performance against
large data volume tables (files), when the grouping results are too big to be
stored in memory. It's done with none concurrent single task mode for parallel
level of 1, 2 and 4 for their respective performances.
Data
Record:

Data
Characteristics:
1. esProc performs better than
Oracle.
2. Oracle is at peak performance
with 2 parallel process. esProc is at peak performance with 4.
7.Analysis
From all use case test we could generally reach the following conclusion on the data characteristics:
1. Oracle normally performs better
than esProc with small data volume concurrent computation; sometimes the
performance advantage could be as high as several times. But there are
exceptions. esProc performs better than Oracle in join computation.
2. For large data volume, single task computation, esProc's performance is higher than Oracle, sometimes the difference can be several times.
3. Performance degrades
significantly both for Oracle and esProc when concurrent number changes from 1
to 2. Oracle still has advantage but the difference with esProc is not too
much.
4. With small data volume
concurrent computation, esProc shows stable performance among each task, while
Oracle demonstrates great variation among different tasks (normally the
difference is up to ten times). However, there are also exceptions. During join
computation, Oracle's performance variation is not big among different tasks,
and parallel is not valid under such condition.
Possible causes for above data characteristics could be as
following:
1.esProc is coded with JAVA,
which is an interpret-execution type of language. Thus the efficiency is lower
than Oracle, which is coded in native C language. Oracle has sophisticated
multi-tier cache mechanism , which perform much better with memory related
computation than esProc. Small data volume parallel computation can normally be
cached, thus Oracle performs better than esProc in such use cases.
2. For large data volume, single
task computation, esProc's performance is always higher than Oracle. This is
due to that large data volume can not be cached, and Oracle's main methods for
performance improvement is not applicable. In such situation, esProc's function
algorithm is more effective, with an obvious advantage.
3. With small data volume
concurrent computation, general performance degrades significantly with the parallel
number changes from 1 to 2, and then to 4. This is a signal that the
computation exceeds the processing power of CPU. Under such conditions, Oracle
still has some advantage, but not too much as compared with esProc. This is
because Oracle does not have the time to read the cache, the only advantage is
native code. From here we can see that Oracle is basically leveraging cache to
improve performance.
4. Since Oracle's cache mechanism
and execution plan can not be managed manually, thus with small data volume
concurrent computation Oracle's performance variation is extremely large,
sometimes the difference is up to ten times.
5. Small
data volume join is an exception. In this case esProc performs one or several
time better than Oracle. Meanwhile the performance variation among each Oracle concurrent task
is small, and parallel is invalid, probably also because that Oracle's cache
mechanism and execution plan can not be managed manually. Thus, join
computation is automatically treated as out-memory computation. Out-memory
computation involves competition for hard disk resources, which leads to the
lack of performance improvement with parallel processing. esProc's parallel
processing is valid, because it can retrieve the small dimension table for
in-memory computation, and thus leverage CPU to do multi-core parallel
computation. The variation among each task is small, possibly also because that
Oracle is automatically treating join as out-memory computation, which does not
require cache, and resource is equally distributed among concurrent processes. With join computation, Oracle's advantage with cache disappeared,
and the performance advantage with native code is limited, whereas the
performance advantage of esProc, as with its use of efficient function
algorithm, is now demonstrated. Thus esProc performs better in such case.
Our basic conclusion for the comparison is: Oracle performs better with small data volume computation, or simple computation with less algorithm. esProc performs better with large data volume, or complicated computations with more algorithm.
Our basic conclusion for the comparison is: Oracle performs better with small data volume computation, or simple computation with less algorithm. esProc performs better with large data volume, or complicated computations with more algorithm.
No comments:
Post a Comment